KotlinLog[0] : The Dark `Side?` of the (nullable) Moon
All about Null safety in Kotlin


![KotlinLog[0] : The Dark `Side?` of the (nullable) Moon](https://cdn.hashnode.com/res/hashnode/image/upload/v1633158265579/SlTriSRPm.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)
Introduction
One of the primary attractions of the Kotlin programming language is that Kotlin's strict typing system distinguishes between nullable types and non-nullable types. This difference exists on the level of the type itself, therefore, the statement "nullable reference to a certain type" is meaningless and the correct statement would be "a reference to a certain nullable type". Technicality aside, this has very profound implications for the way one thinks about their code. For example, consider the following code snippet
fun processString(string: String): String {
val result = StringBuilder()
// process the string in some way
return result.toString()
}
To the untrained eye, the equivalent Java code is as follows
final String processString(final String string) {
final StringBuilder result = new StringBuilder();
// process the string in the same way
return result.toString();
}
However, as it turns out, this is not true.
Firstly, observe that the argument string in the Kotlin is of type String, and not String?, what that means is that null is not a valid instance of String and if one writes processString(null) it should give a type error.
Of course, there is no way to achieve this functionality at compile time in Java and the best one can do is the following
@NonNull final String processString(@NonNull final String string) {
final StringBuilder result = new StringBuilder();
// process the string in the same way
return result.toString();
}
This will allow us to get an underline in the IDE but the following code will still compile:
@Nullable final String input = functionThatCouldReturnNull();
System.out.println(processString(input).charAt(0)); // yikes!!!!! 🤮🤮🤮
In Java, this absolute monstrosity will compile!
Hell, nobody would even realize that there is something wrong until we get a visit from the Devil himself in the form of a java.lang.NullPointerException.
One might make the argument that good Java code is, in fact, of this form
@Nullable final String input = functionThatCouldReturnNull();
if (input != null) {
System.out.println(processString(input).charAt(0)); // no issues 🥰🥰🥰
} else {
// handle null separately
}
In Kotlin, one is forced to write such 'good' code. It is not good code, it is the only possible way.
val input = functionThatCouldReturnNull() // type of `input` is `String?`
if (input != null) {
// Kotlin compiler automatically typecasts `input` to `String` 😎
println(processString(input)[0])
} else {
// handle the case for when input == null separately
}
This is, as it turns out, the only way.
val input = functionThatCouldReturnNull()
println(processString(input)[0]) // compile time error
Kotlin treating nullable types differently from non-nullable is an absolutely beautiful idea.
In all the Kotlin code I've written, I have gotten very few NPEs (you really have to mess up on an ungodly level to get a null pointer in Kotlin). All of them have been my fault (forced typecasting to non-nullable when the problem deserved proper null-handling), however, even more importantly, all the NPEs one can get in Kotlin are deterministic.
You can take a look at the code and tell where the null pointer can originate from. This luxury does not exist in any other language that I'm aware of.
Non-nullable types as subtypes of nullable types
If one thinks of types as sets (this is mostly not a bad idea), the above heading should make absolutely perfect sense. After all, String? contains all possible strings as well as null while String contains all possible strings but not null.
This is the line of reasoning that the Kotlin compiler follows.
So, for example, if one writes
fun toString(any: Any?) {
return any ? "null" : any.toString()
}
This is a valid code. The function takes in an instance of Any?, which means that basically anything can be put into the function. This is because Any? is the universal supertype in Kotlin (analogous to Java's java.lang.Object).
Then we use the 'Elvis operator' so that if any is null, the function returns the string "null", and if it is not null (it is an instance of Any, which also means that now we can invoke functions using this reference), we call the originally defined Any.toString() function.
There is certainly a much better way to deal with this problem using what are called extension functions, but for now, bear with me.
If one now writes
println(toString(null)) // null
println(toString(5 / 3)) // 1
println(toString(httpClient.get("localhost/rest")?.responseCode))
// actual response code if response is non-null else null
We can send basically anything inside that function because Any? is the universal supertype.
However, consider this code
fun toString(any: Any) {
return "${any.javaClass.name}@${any.hashCode()}"
}
This function will never work for any being null. Simply because while null is a valid instance of all nullable types, it is not a valid instance of any non-nullable type. Since Any is the universal supertype of all non-nullable types in Kotlin, any instance of a non-nullable type can be put into the toString(Any) function but no instance of nullable type can be.
Nullability and Inheritance
Kotlin is an object-oriented programming language. This means that, like Java, we can define interfaces and abstract classes and all that good old OOP principles like inheritance and runtime polymorphism apply perfectly well. Kotlin however adds to Java's OOP principles in a few ways, one of them being the universal subtype of Nothing. So while Any? is the universal supertype and produces all other types, Nothing is the universal subtype and consumes all types.
A more detailed explanation of Nothing will come very soon. 😼
However, the fact that non-nullable types and nullable types are separate and follow a parent-child relationship means that inheritance can be a little complicated sometimes.
Just remember two points :
- A nullable type is always the subtype of another nullable type (except
Any?) - A non-nullable type can be the subtype of both nullable as well as non-nullable types
Now, consider the following code
open class Vehicle // open simply means that this class can be extended
class Bus: Vehicle()
class Car : Vehicle()
class Bicycle : Vehicle()
On the surface, this inheritance looks very simple. However, the actual inheritance graph looks like this :
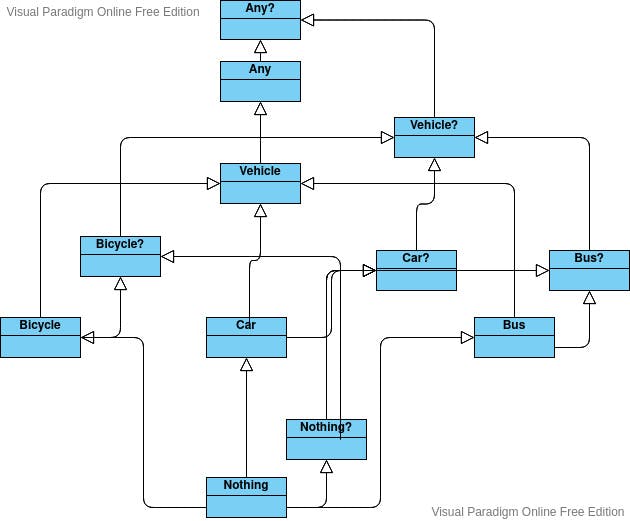
Let's understand with an example:
fun doSomethingWithNonNullableVehicle(vehicle: Vehicle) {
doTheThing(vehicle)
}
fun doSomethingWithVehicleFromDatabase(vehicle: Vehicle?) {
if (vehicle == null) {
logger.info("No vehicle exists in the database for specified parameters")
return
}
// do the thing with vehicle
// vehicle is automatically typecast to `Vehicle` type 😎
doSomethingWithNonNullableVehicle(vehicle)
}
Now, can we put a Bus in this doSomethingWithVehicleFromDatabase, yes!
Because the non-nullable child has a nullable parent in Vehicle?.
Can we put Bicycle? in here?
Hell yes, we can!
The nullable Bicycle? is a child of Vehicle?
What about the first one?
Can we put Bus there?
Yes, we can 😎
Bus is a subtype of Vehicle, not Vehicle? but Vehicle itself is a subtype of Vehicle?.
What about Nothing??
We cannot put Nothing? into the first one since Nothing? is only the universal subtype of all nullable types.
We can, however, put Nothing in there since Nothing is the universal subtype of all non-nullable types and thereby also the universal subtype of all nullable types and therefore the universal subtype of all types.
For the most part, however, this knowledge is theoretical, and Nothing? or even Nothing nearly comes up in practice.
The nullable-access operator
Okay, all this is great but how does one actually work with nullable?
Let's say we have some resources stored in a map. In Kotlin, a map of type Map<K, V> always returns V? and returns null iff the value does not exist.
The fact that null is returned has a specific interpretation is actually very important. A good rule of thumb when writing Kotlin code that returns nullable is that null should have a very specific meaning. This means that null should be treated with the utmost respect and reserved for special occasions.
So let's say we have some map that stores some form of Entry<String, User> maybe returning a user given the username of said user.
We now have two options.
val username = getNonNullableUsernameFromSomewhere() // username is of type `String`
val user = userMap[username] // user has type `User?`
if (user == null) {
// deal with null case
// there is no such user
} else {
// Kotlin compiler automatically typecasts to `User`
performOperationsWithNonNullableUser(user)
}
This is a little inconvenient if there is no convenient way to deal with null or if we want to use Kotlin's default nullability-handling.
In cases such as these, it is convenient to use the nullable-access operator.
val user = userMap[username]
user?.invokeFunctions() // will work if `user` is actually not null 😌
This is, in general, not a good idea. The best way of doing things is to always explicitly deal with possible nulls and have a codebase in which every null has some meaning (such as in the map case where null is returned iff the entry does not exist). In this case, the logical consistency of null-management is maintained.
The nullable-access operator returns null if user is actually null.
But what if invokeFunctions() returns void?
Well, in Kotlin, void doesn't exist. Any valid function must return something. So all functions that do not return anything meaningful return Unit.
So invokeFunctions() too returns Unit on successful execution.
When the call user?.invokeFunctions() fails due to user being null, the code is not executed and instead the value "returned" is null.
val nullableUser = getNullableUserFromSomewhere()
val nonNullableUser = getNonNullableUserFromSomewhere()
val nullableUnit = nullableUser?.invokeFunctionThatReturnsUnit()
// type of `nullableUnit` is `Unit?`
val nonNullableeUnit = nonNullableUser.invokeFunctionThatReturnsUnit()
// type of `nonNullableUnit is `Unit`
For syntactic sugar, the helper function let can make our lives a lot easier and our code a lot more readable
val user = userMap[username]
user?.let {
// `user` is now available as `it`
// `it` is actually non-null
// for `it` we do not need to use the null-access operator 😌
it.invokeFunctions()
}
Of course, the block inside let is executed iff user is not actually null.
Before we move on, I will reiterate, it is best to always check for possible nulls for all nullables and deal with them.
The non-null assertion operator
Let's say we are absolutely sure that something won't be null and we actually want to take the risk of not respecting null and exposing ourselves to NPE.
(Why somebody would do that is beyond me to be very honest)
Well, you can actually do that with the !!
val user = userMap[username]
user!!.invokeFunctions()
We will get an NPE if user is null.
Despite this, I would argue that such a possibility for NPE is very easy to spot and therefore these NPEs are deterministic.
Nullability at the JVM level
Keep in mind that the JVM has no concept of nullability, which means that the compiler does a lot of trickery to ensure that our code is null-safe at runtime. For example, Java code calling Kotlin code cannot violate the null-safety. Let us understand with an example.
fun something(sometype: Sometype) {
// do absolutely nothing
}
One is tempted to think that Java code of the form something(null) would not yield an NPE however, unfortunately, it will.
Even if a non-nullable type is never used, putting null in it's place will lead to an NPE.
Let's look at the bytecode generated by the Kotlin compiler for the above code. I have disassembled the bytecode using the javap tool to make it human-readable. If you don't understand JVM bytecode (again, why would you?) you will still likely be able to follow through. I have intentionally chosen a simple function for which the bytecode is not too complex.
0: aload_0
1: ldc #9
// String sometype
3: invokestatic #15
// Method kotlin/jvm/internal/Intrinsics.checkNotNullParameter:(Ljava/lang/Object;Ljava/lang/String;)V
6: return
We need to know just three things about the JVM in order to understand this bytecode:
- The JVM is stack-based. All operations are done by peeking at the stack and all values that are returned appear at the top of the stack
- The JVM has a "runtime constants pool" and the numbers like #9 or #15 are the indices of constants stored in the pool
- Local variables and arguments to functions are stored in an array and indexing starts from 0.
The first instruction is aload_0, which loads the reference stored in the 0th index of the local variable array (the parameter sometype) to the top of the stack.
The next instruction loads the String "sometype" to the top of the stack.
Then, we use invokestatic to invoke the static function kotlin.jvm.internal.Instrinsics.checkNotNullParameter(Object, String).
This function throws an NPE if the Object entered is null. The String is the name of the parameter. The NPE thrown by the function is something of the form "Parameter sometype is non-nullable".
Conclusion
The null safety provided by Kotlin is absolutely unmatched. Once you understand the different treatment of nullable and non-nullable types it's hard to see how there ever was a language in which this concept doesn't exist (looking at basically every language in the world 😐)
Contact Me
Hi, I'm Rahul Chhabra, I actively work with Kotlin in my projects. Do follow me on Github and LinkedIn